机器学习使优化化学反应变得容易
已经开发出一种易于使用的机器学习工具,可以加速各种合成反应的优化——并揭示认知偏差可能如何破坏人类的优化。
用于合成目标化合物的反应的优化对于化学研究和发现至关重要,无论是开发制造救生药物的路线还是释放新材料的潜力。但是反应优化需要迭代实验来平衡众多耦合变量经常相互冲突的影响,并且经常涉及在数千种可能的实验条件中寻找最佳点。专业合成化学家目前使用简化的模型反应、启发式方法和从观察实验数据中得出的直觉来导航这个广阔的实验空白。在Nature中,Shields等人报告机器学习软件可以优化不同类别的反应,平均迭代次数少于人类所需。
机器学习已成为化学合成各个方面的有用工具,因为它非常适合外推预测模型,这些模型用于通过识别多维数据集中的模式来解决合成问题5。然而,化学家需要学习新技能才能在他们的研究中正确部署机器学习,从而限制了这种方法的广泛采用。Shields等通过报告一个化学家可以轻松采用的开源软件工具包来解决这个问题。
现在有一系列机器学习方法可用,开发任何新应用程序时的首要任务是选择最合适的方法。选择取决于数据类型(数字、图片等)、可用于训练系统的数据点数量以及所需的输出6。错误的选择会导致在训练期间产生错误的相关性,也导致无效的预测模型。
为了训练他们的模型,Shields 和同事选择了一种方法,该方法使用一种称为贝叶斯优化的机器学习方法。贝叶斯优化算法在其他应用中被证明非常有效,但作者是最早开发使用这种反应优化工具包的作者之一。他们的开源软件包含研究人员对具有任意多实验变量的系统进行贝叶斯反应优化所需的所有组件。
该工具包首先使用一个简单的工作流程来执行量子力学计算,该计算以机器可读的格式对感兴趣的反应进行编码,包括所谓的化学描述符7。可以表示为一系列连续数字的反应参数,例如温度和浓度,已经是可以被算法解释的形式。然而,化学家需要使用几种常用的分子符号之一来提供分类的反应参数,例如溶剂或催化剂的特性。
反应中的每个分子随后被工具包分解为描述分子固有化学性质(分子量、电荷密度、键强度等)的数值子集,这些数值可以通过算法8进行解释。将机器学习方法应用于化学系统的一些最大陷阱出现在这个分解过程的执行中。经过多次试验,Shields 和同事找到了一种平衡的方法,可以推广到涉及许多不同化学物质的各种反应。
工作流程的第二部分是贝叶斯优化步骤。正如作者的工作所强调的那样,贝叶斯算法非常适合反应优化,因为它们擅长处理相对较小的数据集9。从稀疏数据开始,该算法创建了一个替代模型,试图在数学上定义输入变量(反应参数)将如何影响输出目标(反应产率或其他性能指标)。
起初,该模型对反应系统提供了较差的近似值,但该算法还会评估在获取新反应数据时学到的知识以测试变量的影响。因此,该算法建议化学家进行一项新实验,为反应变量提供特定值。一旦该实验的数据可用,它们就会被添加到算法中,从而更新模型。然后循环继续,直到反应性能达到指定目标,或试剂耗尽。
Shield等人将此工作流程应用于三个反应类别,其中算法改变了多个反应参数,包括温度、溶剂和配体(与催化剂金属中心结合的分子)。在每种情况下,他们的算法使用大约 50 个测试实验从多达 312,500 个可能的变量组合中成功确定了最佳反应条件。
在使用已发布的数据集对算法调整后,作者使用优化游戏对其性能进行了统计评估,其中该算法与专业化学家竞争。作者选择了一个可以在游戏中优化的反应,然后定义了五个可以改变的反应变量,将玩家限制为每个变量的一组固定可能性:12 个配体、4 个碱基、4 个溶剂、3 个温度和 3 个浓度。然后,研究人员通过实验测试并测量了所有 1,728 种可能的变量组合的结果。
接下来,Shields 及其同事让 50 名化学专家进行了多达 100 次的虚拟优化尝试:参与者选择了 5 个变量组合,然后向他们展示了实验结果,之后他们可以选择新一批的 5 个组合来尝试实现最大可能的反应效率。同样,该算法玩了 50 次游戏,但每次都从随机实验值开始。专家们做出了更好的初始选择,但在第三批实验之后,该算法的平均表现优于玩家(图 1)。
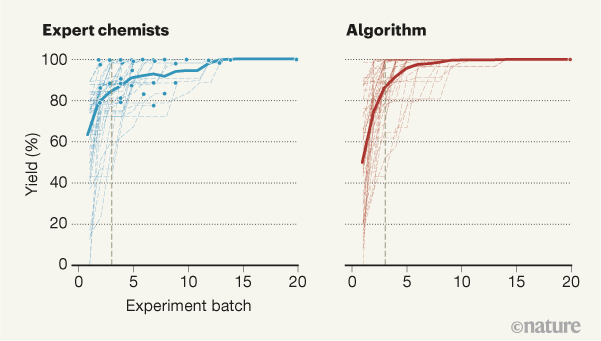
更值得注意的是,该算法始终达到 99% 以上的产率,这只有通过使用一种不常见的配体才有可能,这种配体对于游戏中的目标反应类型来说效果不佳。总的来说,这个游戏提供了一个关于认知偏差的重要教训:大多数化学家提前结束了游戏,只使用了主流试剂,没有意识到他们可以通过做出更冒险的选择来进一步提高产量。Shield等因此开发了一种易于使用的工具,非专家可以使用它来优化各种反应。重要的是,该工作流程可让研究人员完成多种化学物质的编码和优化过程,而无需更改代码。
这种强大的工具准备为化学家提供一种替代反应优化方法,展现机器学习的许多好处。它不仅会加快化学合成研究的步伐,而且还将有助于扩大所测试反应变量的范围。此外,该工具消除了化学家为了减少时间和材料成本而对潜在实验变量进行分类的必要。我希望这项技术能够被广泛采用,从而能够快速优化反应条件并发现不寻常的发现。
Nature 590, 40-41 (2021)